
Le buffer graphémique et ses altérations (2)
Nature des représentations dans le buffer graphémique
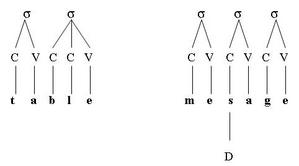
Initialement, Caramazza et al. (1987) ont proposé que les représentations graphémiques étaient encodées de manière linéaire dans le buffer et qu’elles contenaient des informations relatives à l’ordre et à l’identité des graphèmes (par exemple, le mot table serait représenté comme suit : T+A+B+L+E)
Une analyse plus approfondie des erreurs de leur patient LB a par la suite poussé Caramazza et Miceli (1990) à remettre en cause cette première hypothèse relativement simpliste quant à la nature et à l’organisation interne des représentations graphémiques.
Ils ont dès lors suggéré que les représentations graphémiques soient dotées d’une structure multidimensionnelle non linéaire contenant quatre niveaux d’informations : une première dimension contient des informations sur la structure syllabique du mot; une seconde spécifie si les lettres composant le mot sont des voyelles ou des consonnes; une troisième représente l’identité des graphèmes et une quatrième concerne la quantité de lettres contenues dans un mot (cette dimension indique notamment la présence de lettres géminées).
Ainsi par exemple, les mots « table » et « message » peuvent être représentés comme suit [1 voir note de bas de page] :
Différentes observations provenant de l’analyse des erreurs de leur patient LB ont été faites par Caramazza et Miceli (1990) et ont permis d’appuyer leur conception de la structure des représentations graphémiques. En effet, selon eux, les différentes dimensions présentées ci-dessus peuvent être spécifiquement altérées par une lésion cérébrale.
D’autres études sont également mentionnées afin de renforcer ou, au contraire, nuancer l’hypothèse de Caramazza et Miceli.
1. Les mots simples (possédant une structure syllabique telle que CVCVCV) sont écrits plus souvent correctement que les mots complexes (possédant une structure telle que CVCCCV, VCCVCV, CCVCVV par exemple). Selon les auteurs, ce résultat proviendrait du fait que les syllabes simples CV sont plus robustes que les syllabes complexes telles CVC ou CCV ; et donc, la probabilité de faire une erreur au sein de mots ne contenant que des syllabes simples est plus faible que dans des mots plus complexes.
Une observation supplémentaire vient renforcer l’idée selon laquelle les représentations graphémiques contiennent une information sur la structure grapho-syllabique. En effet, il apparaît que le type d’erreurs effectuées par LB est différent selon qu’il doive écrire un mot simple ou un mot complexe. Des substitutions (ex : fanale → farale) et des déplacements de lettres non adjacentes (ex : vagone → gavone) sont fréquemment observés pour les mots simples ; les omissions, les ajouts et les déplacements de lettres adjacentes étant beaucoup plus rares. Au contraire, pour les mots complexes, tous les types d’erreurs apparaissent avec plus ou moins la même fréquence. Les erreurs de type omissions (ex : grembo → gembo), ajouts (ex : taglio → tatglio) et déplacements de lettres adjacentes (ex : crollo → rcollo) ont donc davantage tendance à apparaître dans des clusters de consonnes (CC) ou de voyelles (VV). Les auteurs expliquent ce pattern d’erreurs en invoquant le « Principe de Complexité Minimale » (PCM) selon lequel, suite à l’atteinte d’une représentation graphémique, la séquence grapho-syllabique la moins complexe en fonction de l’information disponible sera produite. Notons que, selon Caramazza et Miceli (1990), la grapho-syllabe la plus simple comprend une consonne et une voyelle (CV).
Selon ce principe, il faut donc prévoir que les erreurs des structures simples s’apparentent à des substitutions et des déplacements de lettres non-adjacentes qui préserveront la structure CV, au contraire d’erreurs telles les omissions.
Le PCM prédit par ailleurs que les erreurs concernant les structures complexes auront tendance à aboutir à des séquences plus simples (CV). Il faut donc s’attendre à observer un grand nombre d’erreurs d’omissions par exemple, dans lesquelles une grapho-syllabe CCV se simplifie en une grapho-syllabe CV (ex : grembo→ gembo).
L’étude de Kay et Hanley (1994) vient quelque peu nuancer ces observations. Leur patient JH ne montre aucune différence de performance entre les mots simples et les mots complexes et ses erreurs ne diffèrent pas non plus selon la complexité des syllabes contenues dans les mots. Ceci contredit l’affirmation selon laquelle les représentations graphémiques encodent l’information concernant la structure grapho-syllabique des mots. Notons cependant que JH est anglophone alors que LB est italophone. Or l’italien est une langue beaucoup plus transparente que l’anglais et contient beaucoup plus de mots avec une structure syllabique simple. Il se pourrait donc que le système graphémique de l’anglais soit légèrement différent de celui employé en italien.
2. Pratiquement toutes les substitutions de lettres respectent le statut de consonnes et de voyelles. En ce qui concerne les substitutions commises par LB par exemple, les consonnes sont remplacées dans 99 % des cas par des consonnes et il en va de même pour les voyelles entre elles (exemple : « civile » devient « cicile » ; « cucina » devient « cucuna »).
D’autres patients présentés dans la littérature montrent un pattern d’erreurs semblable, renforçant l’idée que les consonnes et les voyelles sont encodées séparément au sein des représentations graphémiques et qu’un type d’information (l’identité des graphèmes) peut être perdu sans que l’autre (le statut voyelle/consonne) soit atteint. Il s’agit de JH (Kay et Hanley, 1994), TH (Schiller et al. 2001) et LiB (Cotelli et al. 2003). LiB présente notamment des résultats particuliers. En effet, non seulement la plupart de ses substitutions se font entre consonnes et entre voyelles mais en plus, la majorité des erreurs (85%) concerne des voyelles, indiquant donc, selon les auteurs, que cette patiente serait atteinte d’une altération du buffer graphémique relativement spécifique aux voyelles. Il se pourrait dès lors que, non seulement le statut voyelle/consonne soit encodé indépendamment de l’identité, mais qu’en plus les voyelles et les consonnes soient stockées de manière indépendante dans le système d’écriture (voir aussi Cubelli, 1991 ; cité dans Cotelli et al, 2003). Il faut cependant noter que la dissociation inverse (altération spécifique des consonnes) n’a pas encore été observée en production écrite (mais bien en production orale, voir cependant l’ajout à ce billet : premier commentaire – septembre 2006).
3. La performance de LB pour les consonnes géminées est radicalement différente de ce que l’on observe pour les autres clusters de consonnes : les consonnes géminées sont beaucoup plus résistantes à l’erreur et n’engagent pas les même erreurs que celles impliquées dans les autres clusters de consonnes. En effet, des erreurs concernant spécifiquement les lettres géminées sont présentes. On note ainsi des substitutions qui maintiennent l’information quant à la présence et la place de la lettre géminée (par exemple « sorella » devient « soretta) ou des duplications du caractère géminé (par exemple « sorella » devient « sorrella) ou encore des déplacements de l’information sur le doublement (par exemple « sorella » devient « sorrela »). Par contre, l’introduction d’une geminée dans un mot qui n’en contient pas est très rare. Ceci indique que l’information de gémination est indépendante de celle concernant l’identité des lettres.
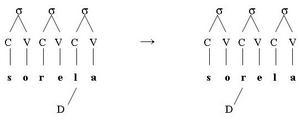
On note également que les deux lettres du cluster géminé ne sont que rarement séparées (par exemple, « sorella » devient « sollera » mais pas « solerla), ce qui renforce l’idée que les consonnes doubles agissent comme si elles n’étaient qu’une seule unité et que cette information est codée indépendamment de l’identité et de la position.

Dans ce cas-ci, l’altération de la représentation du mot sorella a conduit à la suppression des graphèmes (r) et (l ). Il s’est alors produit un échange entre les deux graphèmes cibles, produisant le mot sollera.
D’autres auteurs ont apporté des arguments supplémentaires concernant le statut particulier des lettres géminées. C’est le cas notamment de Tainturier et Caramazza (1996). En effet, même lorsque les informations quant à l’identité et à l’ordre des graphèmes étaient manifestement perturbées, les réponses de leur patient FM avaient tendance à garder l’information de gémination (ex : « giraffe » devient « gafficate » : « raccoon » devient « reaffic »). Des résultats similaires ont également été rapportés par Schiller et al. (2001).
Caramazza et Miceli (1990) ne sont pas les seuls à avoir proposé un modèle multidimensionnel de l’organisation des représentations contenues dans le buffer graphémique. McCloskey et al. (1994) en ont proposé une autre version suite à l’analyse des erreurs qu’ils ont effectuée chez leur patient HE.
Selon eux, les représentations graphémiques incluent au moins trois dimensions : l’une concernant la position des graphèmes, une autre renseignerait l’identité de ceux-ci et enfin, une autre dimension indiquerait si les graphèmes sont des consonnes ou des voyelles (McCloskey n’inclut pas dans son modèle de dimension concernant l’information grapho-syllabique des mots même s’il n’exclut pas le fait qu’elle pourrait facilement y être incorporée). En apparence, ce modèle contient les mêmes informations que dans celui
de Caramazza et Miceli (1990). Cependant, il diffère de ce dernier par la façon dont ces dimensions sont reliées entre elles.
Selon eux, les mots « table » et « message » par exemple, sont représentés comme
suit :
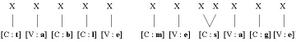
Notons que selon McCloskey et al., les lettres géminées sont donc représentées par un seul élément dans la dimension « identité » associé à deux éléments adjacents dans la dimension renseignant sur la position (représentée par des X).
Ce modèle possède des points communs avec celui de Caramazza et Miceli (1990). En effet, dans les deux cas, les représentations graphémiques sont des structures multidimensionnelles dans lesquelles l’information de gémination est codée indépendamment de l’identité de la lettre qui sera doublée. De plus, les deux modèles prévoient que l’identité de la lettre est représentée indépendamment de son statut consonne-voyelle.
Cependant, on peut également noter des différences entre les deux hypothèses. La représentation des consonnes géminées par exemple diffère selon les modèles.
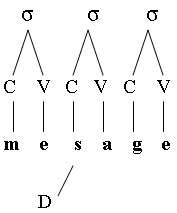
Dans le modèle de Caramazza et Miceli (1990), un lettre géminée correspond à un seul élément dans la dimension « consonne-voyelle » ainsi qu’à un seul élément dans la dimension « identité » :
Par contre, dans le modèle de McCloskey et al, chaque position de lettre dans un mot est représentée séparément. Les deux positions d’une lettre géminée sont donc représentées distinctement dans la dimension « position » :
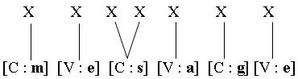
Cette différence permet d’interpréter différemment un type d’erreur particulier que McCloskey appelle les « pseudo-substitutions » (par exemple : dilemma → dilemna, happen → hapren ). Selon le modèle de McCloskey et al., celles-ci correspondraient à une altération de l’information concernant l’identité de la lettre alors que l’information concernant la position elle-même est préservée, par exemple :
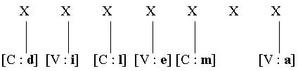
L’erreur de pseudo-substitution proviendrait du fait qu’une nouvelle lettre serait insérée pour rétablir l’équilibre, aboutissant par exemple au mot « dilemna » :
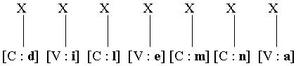
Si, dans ce cas, l’information concernant la gémination (le « D ») est perdu, rien dans la représentation restante ne prévoit d’ajouter une lettre supplémentaire, et l’on devrait dès lors observer une erreur s’apparentant plutôt à une omission : dilemma → dilema.
LB, réalise 5 erreurs de ce type que Caramazza et Miceli interprètent comme étant des erreurs complexes occasionnelles impliquant l’omission d’une des deux consonnes géminées et l’ajout d’une autre consonne.
Selon McCloskey et al, ceci semble cependant improbable. En effet, sur 320 mots contenant une lettre géminée, LB a seulement réalisé 9 omissions au sein de lettres géminées. Il est donc peu vraisemblable qu’il ait effectué 5 erreurs supplémentaires dans lesquelles il a non seulement omis l’information de gémination (le « D ») mais également ajouté une lettre supplémentaire juste à coté de la lettre restante du cluster géminé.
McCloskey et al. concluent donc que cette discordance plaide en défaveur du modèle de Caramazza et Miceli et ils suggèrent donc que leur proposition de représentation des géminées soit prise comme référence.
Un dernier point concernant la nature des représentations graphémiques mérite d’être souligné : les unités contenues dans le buffer graphémique sont amodales. Les représentations graphémiques ne sont par exemple nullement influencées par la phonologie. En effet, on a montré que les erreurs produites par des patients atteints d’un déficit du buffer graphémique aboutissaient à des non-mots souvent non prononçables (Caramazza et Miceli, 1990). Par exemple, en écrivant erronément le mot « carogna » (carcasse en italien), LB, le patient décrit par Caramazza a produit « carocna». Le phonème transcrit « gn » a donc été morcelé. Ceci démontre que l’unité graphémique ne dépend pas de la phonologie : les clusters de consonnes ou de voyelles qui ne correspondent qu’à un phonème se comportent comme si chaque consonne ou
voyelle étaient bien des graphèmes indépendants.
Par ailleurs, les unités graphémiques ne sont pas non plus représentées sous une forme grapho-motrice. Rapp et Caramazza (1997) ont analysé les erreurs de substitutions commises par quatre patients : LB et HE, atteints d’une altération du buffer graphémique ; ainsi que JGE et HL chez qui le déficit était localisé au niveau de processus situés en aval du buffer graphémique. Il s’est avéré que les erreurs commises par JGE et HL présentaient des similitudes grapho-motrices avec les mots cibles (des lettres présentant des traits en commun, comme par exemple « T » et « L »). Par contre, les erreurs de substitutions produites par LB et HE (qui présentaient un déficit du buffer graphémique) n’ont montré aucune ressemblance particulière avec les lettres cibles. Ces données confirment donc que les représentations au sein du buffer graphémique sont amodales.
[1]
Le « D » indique que la lettre à laquelle il est rattaché doit être doublée. Le «σ» se rapporte à la syllabe.
Ping : Des lexèmes aux graphèmes ET des graphèmes aux lexèmes. McCloskey & al, 2006 | Pontt
Ping : Buffer graphémique 3 | Pontt
Ping : Buffer graphémique 1 | Pontt
Adam Buchwald & Brenda Rapp (2006) proposent de nouvelles méthodes pour tester des hypothèses alternatives à l’idée que les représentations orthographiques elles-mêmes contiennent des informations sur le statut C/V des lettres. Ils utilisent ces méthodes afin de tester, auprès de quatre patients atteints d’un déficit du BGS, les hypothèses phonologiques ou orthotactiques (selon ces hypothèses le maintien du statut C/V dans les erreurs des patients proviendrait de la phonologie ou de la connaissance de ce que sont des séquences bien formées de lettres dans l’orthographe d’une langue). Les résultats qu’ils obtiennent chez les patients examinés ne confirment pas ces hypothèses alternatives et renforcent encore la théorie selon laquelle des catégories abstraites telles que C/V sont contenues dans les représentations orthographiques.
Buchwald, A., & Rapp, B. (2006). Consonants and vowels in orthographic representations. Cognitive Neuropsychology, 23 (2), 308-337.
Miceli et al. (2004) ont depuis lors présenté un cas qui fait état de la double dissociation. Leur patient, GSI, avait un déficit localisé au niveau du buffer graphémique de sortie et 98,8% de ses erreurs portaient sur des consonnes. Selon les auteurs, cette double dissociation "voyelles vs consonnes" témoignerait du fait que consonnes et voyelles sont représentées séparément au niveau cérébral. Leurs représentations pourraient donc être altérées indépendemment. Il y aurait dès lors bien une base neuroanatomique à la distinction entre voyelles et consonnes écrites.
Miceli, G., Capasso, R., Benvegnu, B., & Caramazza, A. (2004). Working memory interacts with independent consont and vowel representations in writing. Neurocase, 10, 109-121.